Introduction
Data isn’t just the lifeblood of decision-making—it’s the foundation upon which smart, strategic business moves are built. Today, datasets grow larger and more complex by the minute, making it a necessity to secure data that’s accurate, complete, and consistent. Yet, as critical as this mission is, it’s becoming an ever more Herculean task to tame the wilds of modern data landscapes.
Coalesce emerge as significant player in this field with solutions to the challenges of data quality management it offers a platform for efficient data transformation and workflow management, catering to both code-centric and visual development approaches. With its robust data transformation capabilities, it equips data professionals at any stage with the necessary tools to enforce data quality standards and automate testing processes; Whether you’re a beginner wanting an intuitive experience or a seasoned data pro craving granular control.
Data Quality Testing in Coalesce
Their data quality system revolves around two primary types of tests: Node Tests and Column Tests, each designed to address specific data quality concerns effectively.
Node Tests
These are powerful features within Coalesce, enabling users to write custom SQL SELECT statements that act as conditions for data validation. These tests are incredibly flexible, allowing for a broad range of data quality checks, from verifying data consistency across different nodes to ensuring data transformations are executed correctly. For instance, using Snowflake’s sample data, one might employ a Node Test to validate that transaction totals calculated in a data transformation step align with expected values, highlighting discrepancies that could indicate issues in the transformation logic or source data.
Column Tests
On the other hand, these focus on the granular level of individual columns, checking for null values, ensuring uniqueness where required, and verifying data types. These tests maintain the integrity of data at the column level, running post-transformation to confirm that data conforms to specified constraints and expectations. The recent introduction of “accept values” tests further enhances this capability, allowing users to specify a set of permissible values for a column, thus ensuring that data entries fall within an accepted range.
Together, Node and Column Tests in Coalesce provide a comprehensive framework for automated data quality assurance, enabling organizations to trust their data as a reliable foundation for decision-making.
Coalesce Reusable Tests
We’ve developed these genetic reusable tests for coalesce users. Hosted on our GitHub repository here, they offer a comprehensive set of dbt_utils genetic tests designed to automate and enhance data quality checks within your data workflows. Tailored for the Coalesce platform, they are a blend of algorithms designed to intelligently sift through data, revealing hidden patterns and anomalies. Both novices and professionals can use these tests to flag a wide range of data issues like missing values, duplicate records and inconsistent data formats. They are easy to configure and implement, making them a perfect fit for diverse data environments. You can take a look at them here. They include:
- equal_rowcount: Ensures matching row counts between two datasets.
- row_count_delta: Validates the subset relationship between two tables.
- equality: Asserts the equality of two datasets, with optional column specificity.
- expression_is_true: Checks if a given SQL expression evaluates to true for all records.
- recency: Ensures data freshness based on a specified timestamp column.
- at_least_one: Verifies that at least one record meets the given condition.
- not_constant: Checks for column values not being constant across all rows.
- not_empty_string: Ensures no column contains only empty strings.
- cardinality_equality: Validates that two columns have the same number of unique values.
- not_null_proportion: Confirms a minimum proportion of non-null values in a column.
- not_accepted_values: Checks columns for values outside of an accepted range.
- relationships_where: Validates relationships between tables with a WHERE clause.
- mutually_exclusive_ranges: Ensures that value ranges in two columns do not overlap.
- sequential_values: Checks for sequentially ordered values in a column.
- unique_combination_of_columns: Validates the uniqueness of value combinations across multiple columns.
- accepted_range: Ensures values in a column fall within a specified range.
By integrating these tests into their data validation processes, Coalesce users can significantly enhance data quality, ensuring their datasets are not only accurate but also aligned with their specific business rules and requirements.
Implementation
You can implement these data quality tests:
- Through the user-friendly UI for hands-on interaction
- Programmatically, for those who prefer automating test integration into their data workflows
Each method provides flexibility to suit different user preferences and requirements.
Approach One: Through the UI:
- 1. Log into your Coalesce account.
- 2. Navigate to ”Build Settings” and select ”Macros”
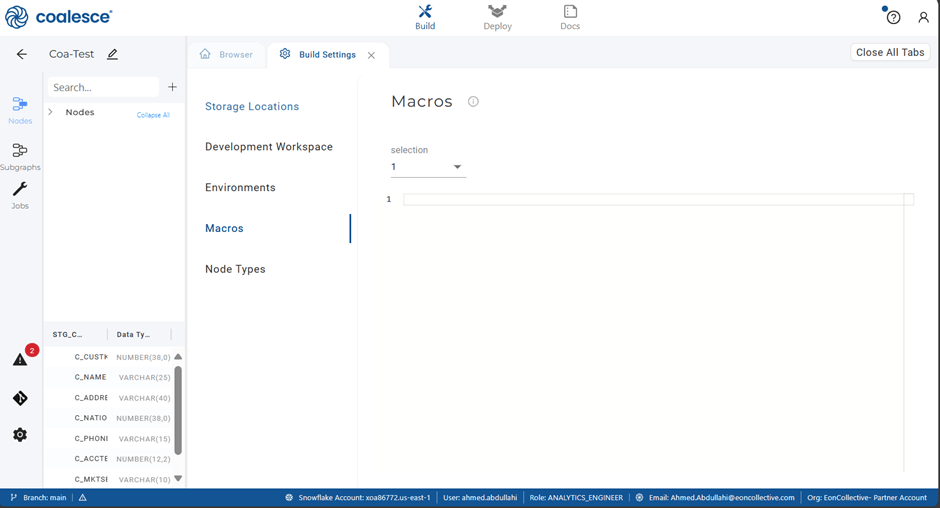
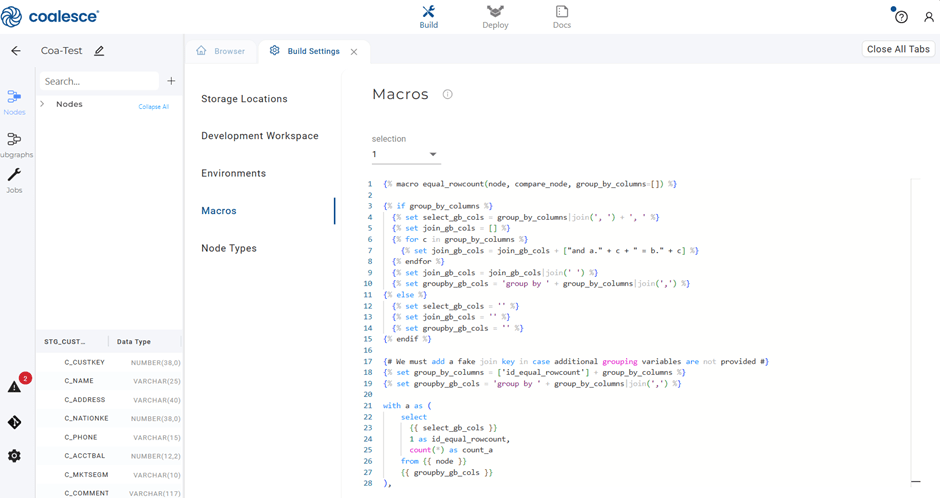
- 3. Access the GitHub repository to select the test you need.

- 4. Copy the test code and paste it into the Macros section within the Coalesce UI.
- 5. To apply tests at the node level, go to your desired Node.
- 6. Activate the Testing toggle and select “New Test”.
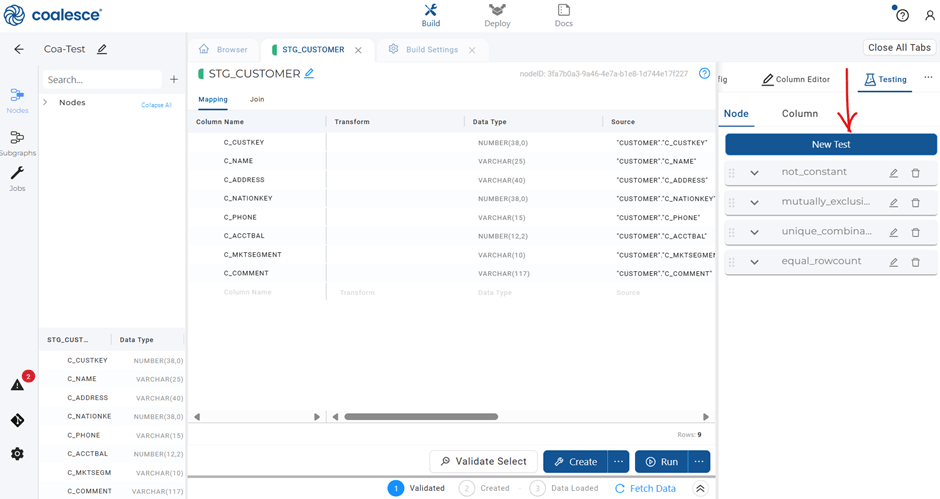
- 7. Refer to the GitHub repository for the specific syntax and examples of the test you are implementing.


- 8. Configure the test parameters as required and save your changes.
Approach Two: Programmatically:
- 1. Clone your Coalesce repository to your local environment.
- 2. Open the repository with your preferred IDE.
- 3. Locate the data.yml file within your project structure.
- 4. Insert the source code of your selected test from the GitHub repository under the macros: section.

- 5. Paste it on your data.yml you’ve opened in the IDE

- 6. Commit and push the changes back to your repository.
- 7. In Coalesce, refresh your project by pulling the latest changes.
- 8. Navigate to the Node you wish to test and click on “Testing” > “New Test”
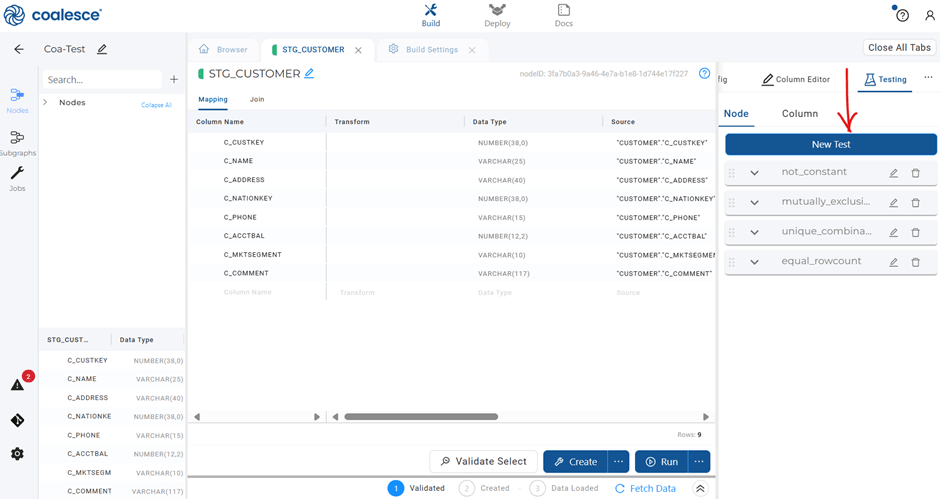
- 9. Use the syntax and examples from the GitHub repo to configure your test.
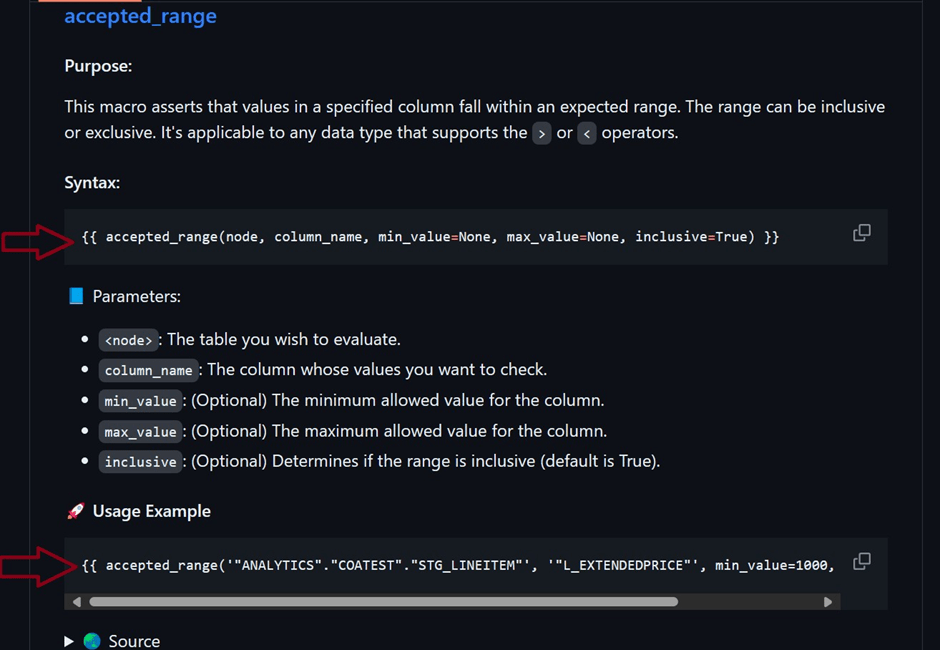

To maximize the benefits of these tests, regularly update the test parameters to align with your evolving data models. Also, integrate these tests into your regular data workflow for continuous quality checks. These suite of tests, accessible through both UI and programmatic interfaces, empower users to implement data quality checks with ease and flexibility. By streamlining the validation process and making it accessible to users of all skill levels, your data remains a trustworthy asset for business insights and decision-making.
We hope this was helpful. Feel free to share your feedback.